|
一: Haproxy有8种负载均衡算法(balance),分别如下: 1.balance roundrobin # 轮询,软负载均衡基本都具备这种算法 2.balance static-rr # 根据权重,建议使用 3.balance leastconn # 最少连接者先处理,建议使用 4.balance source # 根据请求源IP,建议使用 5.balance uri # 根据请求的URI 6.balance url_param,# 根据请求的URl参数'balance url_param' requires an URL parameter name 7.balance hdr(name) # 根据HTTP请求头来锁定每一次HTTP请求8.balance rdp-cookie(name) # 根据据cookie(name)来锁定并哈希每一次TCP请求
/ g9 l) D5 [: @( ]1 G
* b9 K- E! r/ H& h5 o: o& l# Y* @, G
由于负载请求分发到不同服务器,可能导致Session会话不同步的问题,若想实现会话共享或保持,可采用如下3种方式: 1.用户IP 识别 haroxy 将用户IP经过hash计算后 指定到固定的真实服务器上(类似于nginx 的IP hash 指令) 配置指令 balance source 2.Cookie 识别 haproxy 将WEB服务端发送给客户端的cookie中插入(或添加加前缀)haproxy定义的后端的服务器COOKIE ID。 配置指令例举 cookie SESSION_COOKIE insert indirect nocache 用firebug可以观察到用户的请求头的cookie里 有类似” Cookie jsessionid=0bc588656ca05ecf7588c65f9be214f5; SESSION_COOKIE=app1” SESSION_COOKIE=app1就是haproxy添加的内容 3.Session 识别 haproxy 将后端服务器产生的session和后端服务器标识存在haproxy中的一张表里。客户端请求时先查询这张表。 配置指令例举 appsession JSESSIONID len 64 timeout 5h request-learn
! Q4 f& i l0 V- e+ h3 ]
二: 一、haproxy负载均衡实现方式: 3 G0 J! q8 D! _4 U3 t
6 l7 [0 L7 s8 ?$ I- b: L2 W0 c
1、简单的轮询,balance roundrobin;! {6 t* [0 k/ O9 T- F8 @' |
2、根据请求的源IP,balance source;
9 V9 v9 y P. E( Y( o) [; @8 w3、根据请求的uri,balance uri;; D+ x0 C% j% i% Y
4、根据请求URL中的参数,balance url_param;
. ~: z- V- b I; D& v5、根据连接类型,balance leastconn;' z! t$ I3 J; }. o$ h6 g. {+ ^- C
二、详细说明:
* N) I2 O8 O( V# g# ^# c
4 [) X }: a" p3 \3 q8 f1、简单的轮询,balance roundrobin;
\( q% q2 W- C3 q C根据weights(权重)值来分配请求,weights默认为1。0 }* }2 `" h d4 V# N1 V
优点:实现简单,流量按权重分配。' n* \4 \/ I. Z: q+ B
缺点:不够灵活。 8 v( s4 Q8 }7 w$ F
2、根据请求的源IP,balance source;
# I) O* m Q7 Q9 X% q这种均衡方式是对IP源进行hashed运算来匹配。
" e0 U8 K* ^! |. W! j优点:可以保持用户会话(同一IP用户会尽可能访问到同一台服务器)。 c5 k9 M- Q' l6 s. g
缺点:有可能造成单点瓶颈(weights无效)。 + Z& A \; q0 {0 r2 n3 f
3、根据请求的uri,balance uri;
/ N+ m- k% ^* `* c5 l根据客户端请求的URL进行hashed运算来匹配。
" `( c0 i. y& [& ?/ o( K优点:可以提高缓存的命中率(同一URL会尽可能分配到同一台服务器);: s, Y5 Z+ `% n3 ?2 i
缺点:有可能造成单点瓶颈(weights无效)。
5 k3 Y( h+ A2 a1 d9 P4、根据请求URL中的参数,balance url_param。
4 D' e4 G% R0 \# p根据指定URL参数进行hashed运算来匹配。0 A$ m' R5 X" ~; W) v6 l
优点:比较灵活,可以提高缓存的命中率(同一指定参数会尽可能分配到同一台服
* K6 h. E& U2 }! z4 A# T; m3 o务器);
) m) s5 Z; f' Z# M" E8 }+ G* u1 d缺点:有可能造成单点瓶颈(weights无效)。
% b/ C$ M) a+ q3 A. a5、根据连接类型,balance leastconn;# }( m2 e% k$ x4 B9 h9 _* ^
根据连接类型进行匹配。
8 t: e1 {. I& \# {0 t5 j8 b) |! F优点:比较适合长会话的连接,如LDAP, SQL, TSE, etc等;
: S6 i& Q+ x- G. k& U J" C1 G缺点:不适合短会话的连接,如http。
& e0 L( k1 a9 T3 s三: 安装HAProxy及环境配置 红帽的yum源已经为我们提供了最新版本的haproxy,所以我们只需要yum安装即可 [root@node1 ~]# yum install haproxy -y 配置haproxy的日志 编辑rsyslog [root@node1 haproxy]# vim /etc/rsyslog.conf 将以下参数开启 $ModLoad imudp $UDPServerRun 514 加入参数: *.info;mail.none;authpriv.none;cron.none;local2.none /var/log/messages local2.* /var/log/haproxy.log 重启rsyslog [root@node1 haproxy]# /etc/init.d/rsyslog restart 开启转发功能 [root@node1 haproxy]# vim /etc/sysctl.conf 修改参数为: net.ipv4.ip_forward = 1 使内核参数生效 [root@node1 haproxy]# sysctl -p 备份配置文件 [root@node1 haproxy]# cp haproxy.cfg haproxy.cfg.bak 配置文件格式 其大致分为两部分: 全局配置:定义haproxy进程的工作特性,比如进程最多打开多少个文件等 代理配置:需要定义一组前端,再定义后端最后再使其关联起来 ·defaults 供多个前端后端使用的公共配置 ·frontend 相当于nginx的server模块,直接面对用户的配置 -use-backend 其可以使用条件判断 -default-backend 如果条件判断不成立则需要使用默认后端配置 ·backend 后端服务器配置信息 ·listen 运行的主机配置信息 在以上四个代理配置上,每种下面还可能有许多专用的或者公共的,被称为代理属性配置 以服务配置文件为例 defaults mode http log global option httplog option dontlognull optionhttp-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeouthttp-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeouthttp-keep-alive 10s timeout check 10s maxconn 3000 每一个frotend都可以定义日志的,那日志的时候每个日志都可以定义2个,如果期望与全局不一样的话都可以自行定义 这里有timeout参数,所以其不可避免用到很多时间单位,比如毫秒微妙 秒 分钟 小时 等,必须要定义时间单位的 性能调整相关的参数 - maxconn <number>:设定每个haproxy进程所接受的最大并发连接数,其等同于命令行选项“-n”;“ulimit -n”自动计算的结果正是参照此参数设定的;只要设定以后 ulimit -n会根据maxconn做自动计算的 - maxpipes <number>:haproxy使用pipe完成基于内核的tcp报文重组,此选项则用于设定每进程所允许使用的最大pipe个数;每个pipe会打开两个文件描述符,因此,“ulimit -n”自动计算时会根据需要调大此值;默认为maxconn/4,其通常会显得过大;每个管道都打开至少两个文件,因为一开一合两段需要两个文件描述符 - noepoll:在Linux系统上禁用epoll机制; - nokqueue:在BSE系统上禁用kqueue机制; - nopoll:禁用poll机制; - nosepoll:在Linux禁用启发式epoll机制; - nosplice:禁止在Linux套接字上使用内核tcp重组,这会导致更多的recv/send系统调用;不过,在Linux 2.6.25-28系列的内核上,tcp重组功能有bug存在;实现零复制的机制 - spread-checks <0..50, inpercent>:在haproxy后端有着众多服务器的场景中,在精确的时间间隔后统#检查上游server,将请求分散开来,分先后不会并发出去,所以其表示将检测机制分散开,数值可以是0-50表示百分比,比如定义2秒钟检查一次,其会在两秒钟的机制上随机增加原有时间的百分之几,但对众服务器进行健康状况检查可能会带来意外问题;此选项用于将其检查的时间间隔长度上增加或减小一定的随机时长; - tune.bufsize <number>:设定buffer的大小,同样的内存条件小,较小的值可以让haproxy有能力接受更多的并发连接,较大的值可以让某些应用程序使用较大的cookie信息;默认为16384,其可以在编译时修改,不过强烈建议使用默认值; - tune.chksize <number>:设定检查缓冲区的大小,单位为字节;更大的值有助于在较大的页面中完成基于字符串或模式的文本查找,但也会占用更多的系统资源;不建议修改; - tune.maxaccept<number>:设定haproxy进程内核调度运行时一次性可以接受的连接的个数,较大的值可以带来较大的吞吐率,默认在单进程模式下为100,多进程模式下为8,设定为-1可以禁止此限制;一般不建议修改; - tune.maxpollevents <number>:设定一次系统调用可以处理的事件最大数,默认值取决于OS;其值小于200时可节约带宽,但会略微增大网络延迟,而大于200时会降低延迟,但会稍稍增加网络带宽的占用量; - tune.maxrewrite<number>:设定为首部重写或追加而预留的缓冲空间,建议使用1024左右的大小;在需要使用更大的空间时,haproxy会自动增加其值; - tune.rcvbuf.client<number>: - tune.rcvbuf.server<number>:设定内核套接字中服务端或客户端接收缓冲的大小,单位为字节;强烈推荐使用默认值; - tune.sndbuf.client: - tune.sndbuf.server: 配置简单反向代理 规划如下: 启动web服务器 [root@mode ~]# /usr/local/apache/bin/apachectl start 配置网关 [root@mode ~]# route add default gw 10.0.10.61 [root@mode ~]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 10.0.10.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1 172.23.214.0 0.0.0.0 255.255.254.0 U 0 0 0eth0 169.254.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth1 0.0.0.0 10.0.10.61 0.0.0.0 UG 0 0 0 eth1 0.0.0.0 172.23.215.254 0.0.0.0 UG 0 0 0 eth0 测试可否ping通haproxy的另外一块网卡 [root@mode ~]# ping 10.0.0.61 PING 10.0.0.61 (10.0.0.61) 56(84) bytes of data. 64 bytes from 10.0.0.61: icmp_seq=1 ttl=64 time=61.2 ms 查看web服务是否正常 [root@node1 haproxy]# curl http://10.0.10.839 Y1 H# |) w. w7 s/ M! J$ x* f# u( _
<h1>10.0.10.83</h1> 配置反向代理 [root@node1 haproxy]# pwd7 [! w$ {1 t# ^
/etc/haproxy 定义前端 只要使用frontend 跟上名称即可,如下所示: #---------------------------------------------------------------------
+ I; V' O7 R( Hfrontend webserver #明确说明web服务器监听在80端口上 bind *:80 #用来监听地址和端口,我们可以监听多个地址 default_backend appservs #使用默认backend,不管是哪个请求统统发往appservs,这里使用的appservs一定是在backend中使用的appservs #--------------------------------------------------------------------- # round robin balancing between the various backends
/ r: ~6 |) f- @! S7 r4 R#--------------------------------------------------------------------- backend appservs
y j* k ?% | server web1 10.0.10.83:80 check #check表示对其做状态监测 保存退出并重启服务 [root@node1haproxy]# /etc/init.d/haproxy restart [root@node1 haproxy]# netstat -lntp | grep 80 tcp 0 00.0.0.0:80 0.0.0.0:* LISTEN 2568/haproxy 访问haproxy的80端口并查看 [root@node1 ~]# curl http://localhost <h1>10.0.10.83</h1> [root@node1 ~]# curl http://10.0.10.61 <h1>10.0.10.83</h1> 这样就将frontend和backend结合了起来,我们可以甚至用一个listen进行定义,修改配置文件,如下所示: #frontend webserver listen webserver #只定义一个listen bind *:80 # default_backend appservs #backend appservs server web1 10.0.10.83:80 check [root@node1 haproxy]# /etc/init.d/haproxy restart 重新访问测试: [root@node1 haproxy]# curl localhost <h1>10.0.10.83</h1> [root@node1 haproxy]# curl 10.0.10.61 <h1>10.0.10.83</h1> 混合使用frontend和backend 我们期望定义backend 名称为imgser,使其充当img服务器 backend imgser
5 Y0 G6 {5 j a* p4 F W server img1 10.0.10.83:80 check 调用后端server listen web_server bind*:80 server img1 10.0.10.82:80 check #修改为新的web server 地址 frontend img_server bind *:8080 #haproxy无法实现基于虚拟主机的方式来定义 default_backend img_server #调用backend定义的imgser 在web节点加入临时ip [root@mode ~]# ifconfig eth0:0 10.0.10.82 重新启动haproxy,查看其监听端口 [root@node1 haproxy]# netstat -lntp | grep 80 tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN 4695/haproxy tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 4695/haproxy 并访问测试 [root@node1 haproxy]# curl localhost:8080 <h1>10.0.10.83</h1> 配置状态输出管理页面 状态页面需要独立定义,需要明确说明要启动页面,可以在某个listen或者backend加入开启参数 如下所示: listen web_server( O8 Q. w( a7 {4 ?4 {# Y0 M, U+ r
bind *:80
) T2 X" K) j% J server web1 10.0.10.83:80 check
) A4 M3 z5 y. K4 B' ]7 R7 ^ stats enable 保存退出并重启服务,访问其状态页面,默认页面是路径uri为: url/haproxy?stats 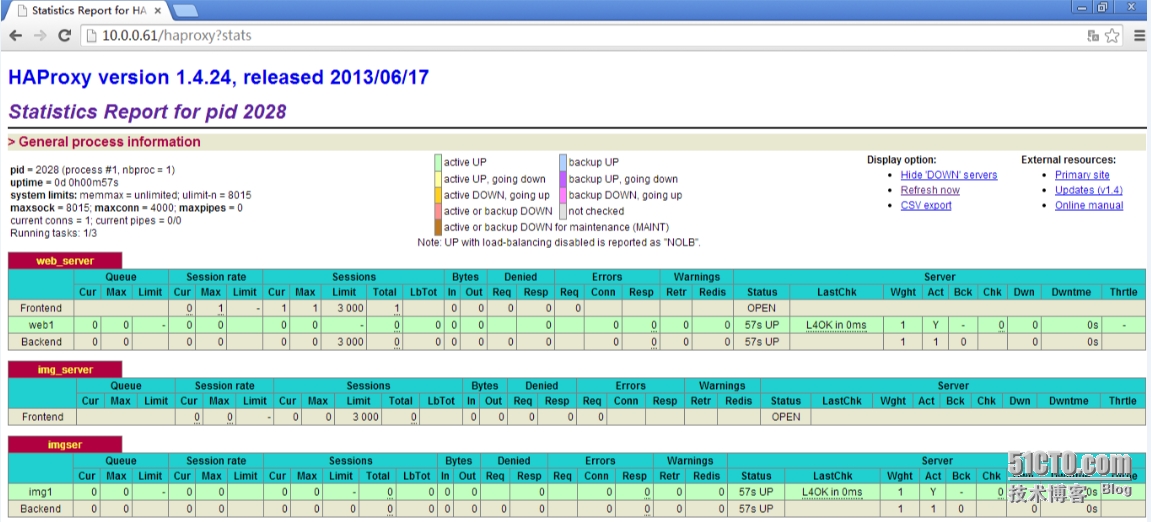
页面明确显示其分类 (backend/frontend)而且其页面状态非常客观,各状态的颜色明确显示。我们将一个服务关闭并观察其页面状态 将web服务的某个ip禁用并观察其状态 [root@mode ~]# ifconfig eth0:0 down 再次刷新页面并查看 
隐藏版本信息 listen web_server
7 K( H0 ^/ e& N' r6 D bind *:80! l: G; W3 z1 B# @4 c: x6 x m4 v7 Z
server web1 10.0.10.83:80 check, O# B4 j9 k4 f- t4 Q4 @
stats enable
* _- d: u$ \# P% f stats hide-version 对状态页面做认证登录 对于管理页面来说,不对其做认证是非常危险的,所以haproxy有自带的密码认真机制,只要在配置文件中配置好用户名以及密码即可,如下所示 listen web_server5 q, F" N6 F: `! B# \% L* P
bind *:80) I& x, @( P- l
server web1 10.0.10.83:80 check
3 r' b7 T1 t& g6 n stats enable
- I- U3 V# i( w% Z stats hide-version
: |8 \- b E- V stats realm HAProxy\ Status #标题* C9 O6 s6 z7 M/ H* ]1 E5 P0 X, X/ a
stats auth admin:admin888 #密码 访问测试: 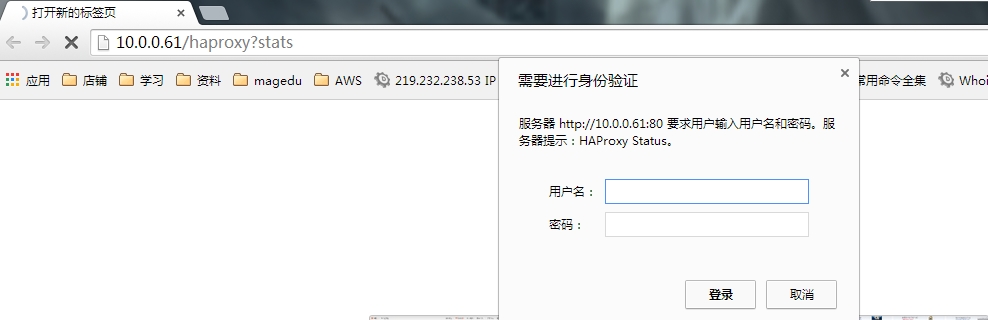
定义页面管理功能 定义页面管理功能后,可以对其上游服务器进行上线和下线等一系列常用管理操作,使其管理更加方便,也是haproxy的特性之一 配置如下: listen web_server bind *:80 server web1 10.0.10.83:80 check stats enable stats hide-version stats realm HAProxy\ Status stats auth admin:admin888 3 T8 [ a) }7 u
stats admin if TRUE #开启页面管理 * W: N; ]) Y$ U
& ~* @! c& h/ i v8 \% r
查看页面信息 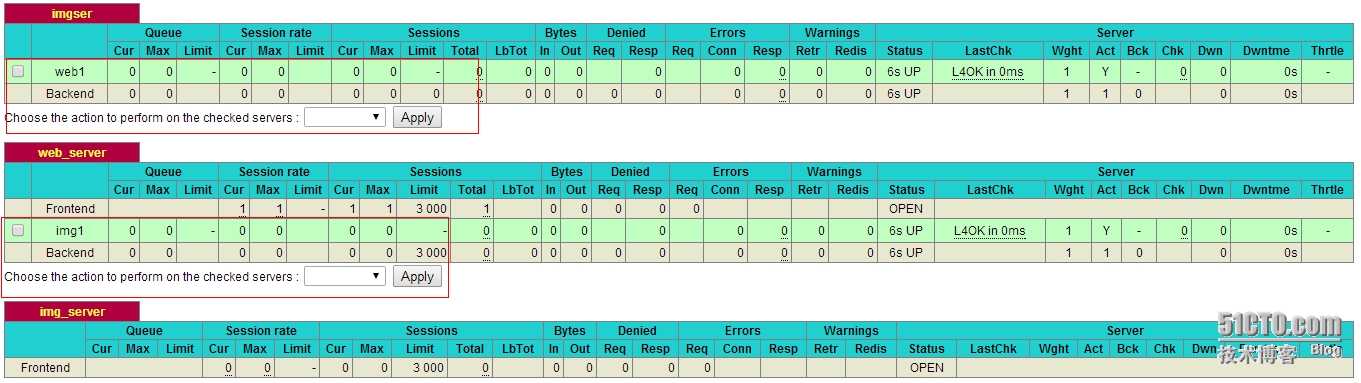
可在选项中对服务进行软启动或关闭(在前端启动或关闭),可以非常方便的在前端直接将某一服务器调度为维护,当服务器出故障了可将其先关闭然后维护再让其上线,非常便捷 在管理页面中,让其中一台server下线: 选中Disable然后选择Apply 
可以看到其页面处于down的状态,是不是很方便? 
更改管理页面URL 如果还是使用的默认url,暴露在外很容易被暴力破解,为了更好的安全性,haproxy可以自定义其管理页面,如下所示 listen web_server bind *:80 server web1 10.0.10.83:80 check stats enable stats hide-version stats realm HAProxy\ Status stats auth admin:admin888 stats admin if TRUE
2 s1 J/ ]" L# Z& J$ { stats uri /abc - f* F0 ?2 C B. ~# o* B. q
j) Y+ B6 P2 g+ a. s' a/ t+ q访问测试: 
将stats更改端口使外人难以猜测url 单独定义listen,归档好,为了更方便的管理 listen web_server bind *:80 server web1 10.0.10.83:80 check
, C) J0 |/ l2 h) l ^& d: m1 h
#单独定义一个listen listen stats bind *:54321 #定义 stats enable stats hide-version stats realm HAProxy\ Status stats auth admin:admin888 stats admin if TRUE . q$ `/ ^" ]! P' Q# `" v2 b
stats uri /admin?admin `1 l5 n6 [8 ^
重新加载配置文件后访问 # /etc/init.d/haproxy restart
1 h; b f9 @" P" n) h6 }' V访问地址http://10.0.0.61:54321/admin?admin,可以看到管理页面,内容只不过多了个stats 
配置负载均衡 假设我们只想提供一组server(2台web),然后以负载均衡的方式进行访问 frontend web_server bind *:80 default_backend webservers ! d+ {8 h1 R8 {; K- j( u
listen stats bind *:54321 stats enable stats hide-version stats realm HAProxy\ Status stats auth admin:admin888 stats admin if TRUE stats uri /admin?admin 1 o) G/ D/ X, D& {. m+ f% `
#--------------------------------------------------------------------- # round robin balancing between the various backends #--------------------------------------------------------------------- ( _- T2 R! ]( e; D& s6 B
backend webservers server web1 10.0.10.82:80 check 8 J; R0 {/ v' E1 G5 k; @, }! W4 A
server web2 10.0.10.83:80 check 7 K4 k) B& R! f7 W
9 J' B+ [* E1 \7 E
重启服务并查看 
服务运行正常,我们来访问一下并测试: <h1>10.0.10.82</h1> <h1>10.0.10.83</h1> <h1>10.0.10.82</h1> 7 a& L" m3 a+ H3 B
<h1>10.0.10.83</h1>
* i% c. f' { F% [2 L
" h& ?) N6 M1 T7 J/ i, j
9 g* z# U" M3 h! T: T6 L, W1 y9 v- V- `$ {6 Q% G
5 |5 s! R0 ~. \
已经达到了负载均衡的效果,但是其分发是轮询的方式,如果我们想让其一直保持会话该如何做呢,请继续往下看 使其保持session 所有的动态调度方法的特性 1.更改权重,权重可在服务器运行时调整,而且不用重启服务即可生效 2.支持慢速启动,将一部分连接请求慢慢过渡至新上线的realserver ·更改权重 server web1 10.0.10.82:80 check weight 3
, Y; W, w' x y" G7 t: B, l server web2 10.0.10.83:80 check weight 1 8 w, T6 Q' ^% y' m! Q
更改完毕重新加载配置文件即可,再次访问并查看结果 [root@node1 haproxy]# curl http://10.0.10.61 <h1>10.0.10.82</h1> <h1>10.0.10.82</h1> <h1>10.0.10.82</h1>
% v6 g j9 b7 x# R4 e, R. a2 U9 {<h1>10.0.10.83</h1>
4 U3 c: j8 Z+ K" @ 慢速启动 主要可以将一部分连接请求慢慢过渡至新上线的realserver HAproxy的调度算法 roundrobin 所谓的动态调整才支持慢速启动,但是这种方法有个限定,每组backend最多接受4095个服务器,而且不用管它,因为后端有40台服务器就算很大的规模了,所以不用在意这些细节问题 leastconn 最少连接,考虑到后端的连接状况,所谓最少连接,也是基于权重来做最少连接的,类似于lvs的wlc算法,哪个连接数少则将请求分配至哪个server,但需要注意的是并不适用于web场景,如果后端是web服务器的话,不建议使用此方法,rr算法最好,因为官方文档上明确说明,只建议使用建立连接时间非常长的会话,比如ssh ldap sql协议等,对于web来讲,连接建立和断开的非常频繁,除了额外增加一些检测机制之外没有太大的意义,如果不考虑做ip地址绑定的话,最好的算法还是roundrobin,但如果是动态服务器,我们需要保持会话。nginx使用的是ip hash算法,而haproxy使用的是source算法 source 将每一个源ip地址都做成hash码,键是客户端ip地址的hash,而目标则是挑选过的ip,所以同一ip来访问过了都会被定向至同一个upstream server(realserver)中去,类似于nginx的ip_hash算法,这种算法对于后端服务器的调整方式,还受另外一个参数的影响 "hash-type" 是动态的还是静态的还需要取决于hash类型 Hash类型 hash类型分为两种: 1.map-based 如果使用map-based,那么source则是静态的; 2.一致性哈希 如果使用一致性哈希 那么source则是动态的; 总结 roundrobin 动态的 static-rr 静态的 hash-type 取决于hash类型 map-based 静态 consistent 动态 支持服务器调整,支持慢速启动 Map:默认类型是,但用户第一次来访问的时候,表中没有任何的信息,会自动计算源iphash码除以服务器数量,余数得几就是第几台服务器(取余)并将请求分发至此台服务器 一致性哈希:将所有的服务器放在哈希环,每个哈希都有自己的范围.....(详情查看之前发布的博文memcache章节) 使用source方式使其生效 配置其为source算法,如下所示: backend webservers balance source #定义source算法 hash-type consistent #使用的哈希类型为 consistent server web1 10.0.10.82:80 check weight 1
( @' r. d4 E- \3 D server web2 10.0.10.83:80 check weight 1 ! j9 E% f8 Y! F' d& _7 m
4 d# M. i! v1 c5 t* v1 |重新加载配置文件并访问测试 <h1>10.0.10.82</h1> <h1>10.0.10.82</h1> <h1>10.0.10.82</h1> <h1>10.0.10.82</h1> <h1>10.0.10.82</h1>
' X r1 @4 Z& ?8 o o2 X<h1>10.0.10.82</h1>
; l# |0 l2 }- J/ V; n0 o
% p, n! Z4 ^# e7 h
2 O+ U: p# f8 ~% N9 P3 D
8 n+ J# }% v3 D7 K! q
可以看到,已经建立会话保持,那么我们让82下线,并观察 
再次访问 0 Q: u n' r$ J) H8 ~
<h1>10.0.10.83</h1>
* X: n& W3 T# A6 c6 g
. ~: k" @4 W5 W使其web1上线,并再次访问测试: <h1>10.0.10.82</h1>
4 U" V4 @, o% w. [% U<h1>10.0.10.82</h1>
% H9 ~* M- m' g5 t h5 p' s
; ?: j& x5 d0 n+ W! \
) k3 m: a% O% C- h
其又回到web1上了,因为会话表中此前保存的有结果,结果不会被删掉的,因此之前的节点挂掉,只是被重定向至web2,而不是改了会话表 按理来讲,hash表在失效之前一定会发往同一个服务器,无论服务器在不在线,但这一来会导致一个结果: 一旦服务器故障其他人则不会访问到,因此它会再定向至其他服务器,但这一来不当紧,所有的会话就失效了,如果想保持永久会话则需要共享存储,我们讲用户的会话可以放到memcached当中等,使用共享会话,所以在负载均衡中最恶心的就是会话的问题,保持会影响均衡效果,不保持则会导致用户的行为无法追踪 uri - 专用于缓存服务器 将此前不管是哪个ip或哪个用户,只要是分配过的地址,一定将同一个uri到同一个server上去,所以这种场景特别适合后端是缓存服务器 backend webserver balanceuri hash-type consistent server web1 10.0.10.82:80 check weight 1 6 O1 y2 H T) @+ _/ _/ j
server web2 10.0.10.83:80 check weight 1
3 c2 L2 R4 V& }
6 ~$ D: m3 z# q& Y2 f1 n
" K j T. T( P A/ B8 M3 V$ i) d
! F: @4 P+ \ P$ y) s( }" H8 z
创建后端server页面 ( |1 y& \6 E' l' N
[root@mode php_test]# fori in {1..10}; do echo "83.$i" > $i.html;done
q5 {) m5 @* w8 a% ][root@mode php_test2]# for i in {1..10}; do echo "82.$i" > $i.html;done 3 ?, \ Z6 W- {' d7 \! z3 S2 }
% G6 q& Z6 e6 v1 {; j/ [
- ]# Z( S* {( ~/ H0 a6 Y重启服务并访问测试 只要uri是同一server的,那么访问的肯定是同一server的 83.1 83.1 83.2 83.2 82.4 82.4 83.7 83.7 82.9
- i1 p O* F; S( N82.9
2 I. w4 h% A8 g$ u7 Z- g
* I& }# ?* j: A9 c% ^1 @- E
( C! s8 r) A: |
/ b+ e8 V! c; Y& a# `6 r, Z
可以看到其效果,因此这种方式最适合调度缓存服务器的 url_param 只对get方法做调度,而且调度只根据url参数做调度; 主要追踪用户标示,来自标示同一个用户id都发往某一服务器(将同一用户账号的请求都发往同一台或同一组服务器) 适用于电商站点 hdr header的简写 首部分类: request header resporse header 有些只能用在响应有些用在请求上 比如后端有不同的虚拟主机,但是在haproxy中,用户的请求都是通过dns解析之后发往我们的haproxy外网地址,那么可以通过hdr来实现对于域名或虚拟主机进行分发至不同的虚拟主机 #根据用户请求的host做转发 hdr(Host) host: www.a.com host: www.b.com , Z9 L4 |& u) _/ Z+ z
3 y& }; D' U' J, t; o3 k |




 发表于 2017-9-8 09:50:44
发表于 2017-9-8 09:50:44