|
Filter scheduler 是 nova-scheduler 默认的调度器,调度过程分为两步: : O& w& A$ ] A, Y, d" p
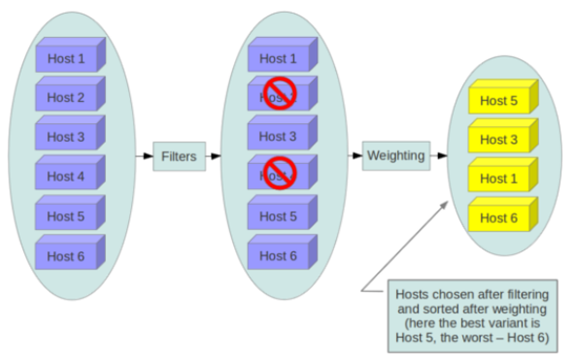
通过过滤器(filter)选择满足条件的计算节点(运行 nova-compute) 通过权重计算(weighting)选择在最优(权重值最大)的计算节点上创建 Instance。 0 m& J9 d* W( X' X8 p( P; h
Nova 允许使用第三方 scheduler,配置 scheduler_driver 即可。
" s! \" A5 P( _( Y* i6 A5 wScheduler 可以使用多个 filter 依次进行过滤,过滤之后的节点再通过计算权重选出最适合的节点。
2 d2 ^5 t0 s; f6 \3 n6 @. q8 G5 }
8 C/ Q i. r+ I: M3 w5 b% j目前,openstack默认支持几种过滤策略,开发者也可以根据需要实现自己的过滤策略。在nova.scheduler.filters包中的过滤器有以下几种: l AllHostsFilter – 不做任何过滤,直接返回所有可用的主机列表。 l AvailabilityZoneFilter – 返回创建虚拟机参数指定的集群内的主机。 l ComputeFilter – 根据创建虚拟机规格属性选择主机。 l CoreFilter – 根据CPU数过滤主机。 l IsolatedHostsFilter – 根据 “image_isolated” 和 “host_isolated” 标志选择主机。 l JsonFilter – 根据简单的JSON字符串指定的规则选择主机。 l RamFilter – 根据指定的RAM值选择资源足够的主机。 l SimpleCIDRAffinityFilter – 选择在同一IP段内的主机。 l DifferentHostFilter – 选择与一组虚拟机不同位置的主机。 l SameHostFilter – 选择与一组虚拟机相同位置的主机。
) C: K$ J0 q/ O1 O! u
4 j/ [: P$ g. |, }$ H【RetryFilter】 # F9 } U0 w& x' `
RetryFilter 的作用是刷掉之前已经调度过的节点。 " G" p% K% q9 H6 \* ~
举个例子方便大家理解: 假设 A,B,C 三个节点都通过了过滤,最终 A 因为权重值最大被选中执行操作。 但由于某个原因,操作在 A 上失败了。 默认情况下,nova-scheduler 会重新执行过滤操作(重复次数由 scheduler_max_attempts 选项指定,默认是 3)。 那么这时候 RetryFilter 就会将 A 直接刷掉,避免操作再次失败。 RetryFilter 通常作为第一个 filter。 9 }: U+ S B- E2 Q' T6 B. C! b2 X
【AvailabilityZoneFilter】 # f2 x% ~$ A. h+ M1 m5 p9 P
为提高容灾性和提供隔离服务,可以将计算节点划分到不同的Availability Zone中。 ) i' S+ S) O9 g7 Q! @. T/ n5 _
例如把一个机架上的机器划分在一个 Availability Zone 中。 OpenStack 默认有一个命名为 "Nova" 的 Availability Zone,所有的计算节点初始都是放在 "Nova" 中。 用户可以根据需要创建自己的 Availability Zone & W$ I# M0 F# L7 X& X0 J
【RamFilter】 & ~" d( p: r( c3 h0 L
RamFilter 将不能满足 flavor 内存需求的计算节点过滤掉。 内存超分: 对于内存有一点需要注意: 为了提高系统的资源使用率,OpenStack 在计算节点可用内存时允许 overcommit(超售),也就是可以超过实际内存大小。 超过的程度是通过 nova.conf 中 ram_allocation_ratio 这个参数来控制的,默认值为 1.5 ram_allocation_ratio = 1.5 |
. o+ |$ o# p5 F1 N% i4 I' w$ N) E8 h3 p
其含义是:如果计算节点的内存有 10GB,OpenStack 则会认为它有 15GB(10*1.5)的内存。 2 S/ d, d* `1 C0 c! K$ f
【DiskFilter】
2 g% L; I e* u0 ?, x, h5 w4 c/ _DiskFilter 将不能满足 flavor 磁盘需求的计算节点过滤掉。 磁盘超分: Disk 同样允许 overcommit,通过 nova.conf 中 disk_allocation_ratio 控制,默认值为 1
0 a/ Z% f$ H& f8 cdisk_allocation_ratio = 1.0 |
) r) T1 s" X3 h: M
$ o' p4 s8 l0 Y6 l/ X& L A4 z【CoreFilter】 + L( U9 Y. J: t3 B. c# V" F; o
CoreFilter 将不能满足 flavor vCPU 需求的计算节点过滤掉。 cpu超分: vCPU 同样允许 overcommit,通过 nova.conf 中 cpu_allocation_ratio 控制,默认值为 16 7 E' L0 s! ]+ P+ ^% J
cpu_allocation_ratio = 16.0 |
( G7 P: ~8 J: y3 S这意味着一个 8 vCPU 的计算节点,nova-scheduler 在调度时认为它有 128 个 vCPU。 需要提醒的是: nova-scheduler 默认使用的 filter 并没有包含 CoreFilter。 如果要用,可以将 CoreFilter 添加到 nova.conf 的 scheduler_default_filters 配置选项中。
" ]4 C# n+ ]7 |+ M, C; s" \2 y
9 s* K- `8 x) ^ Q* X! T6 ?1 [( E
【ComputeFilter】
' v2 o& E3 B) v) iComputeFilter 保证只有 nova-compute 服务正常工作的计算节点才能够被 nova-scheduler调度。 ComputeFilter 显然是必选的 filter。
' X- W, I6 K. o# l! n; R' N【ComputeCapabilitiesFilter】 - {( K% {4 s( k& @
ComputeCapabilitiesFilter 根据计算节点的特性来筛选。
# z; ]+ F+ P9 V2 J8 \这个比较高级,我们举例说明。 例如我们的节点有 x86_64 和 ARM 架构的,如果想将 Instance 指定部署到 x86_64 架构的节点上,就可以利用到 ComputeCapabilitiesFilter。
3 ?! r( C+ K" ^+ g还记得 flavor 中有个 Metadata 吗,Compute 的 Capabilitie s就在 Metadata中 指定。
" y( p& c+ [! ~% @/ s【ImagePropertiesFilter】
; i0 z& f: v6 |4 M* ? r: dImagePropertiesFilter 根据所选 image 的属性来筛选匹配的计算节点。 跟 flavor 类似,image 也有 metadata,用于指定其属性。
" R( N# y# k! y+ ?' e. d0 R7 ^【ServerGroupAntiAffinityFilter】
3 D8 v" z! `* u0 GServerGroupAntiAffinityFilter 可以尽量将 Instance 分散部署到不同的节点上。
1 Y3 F- B$ x: B; f【ServerGroupAffinityFilter】
9 C0 T8 T! b2 c0 K0 y7 `与 ServerGroupAntiAffinityFilter 的作用相反,ServerGroupAffinityFilter 会尽量将 instance 部署到同一个计算节点上。 6 \1 C3 s% ]6 y0 E6 w% o( ?: \
【Weight】 5 b$ {* P) W1 m# f) j1 f
经过前面一堆 filter 的过滤,nova-scheduler 选出了能够部署 instance 的计算节点。 如果有多个计算节点通过了过滤,那么最终选择哪个节点呢?
% M7 P& x. F9 n6 J( xScheduler 会对每个计算节点打分,得分最高的获胜。 打分的过程就是 weight,翻译过来就是计算权重值,那么 scheduler 是根据什么来计算权重值呢? 6 d8 O, p) }5 a7 {, h0 [% M1 Q
目前 nova-scheduler 的默认实现是根据计算节点空闲的内存量计算权重值: 空闲内存越多,权重越大,instance 将被部署到当前空闲内存最多的计算节点上。 |




 发表于 2022-6-10 22:00:14
发表于 2022-6-10 22:00:14