马上注册,结交更多好友,享用更多功能,让你轻松玩转社区。
您需要 登录 才可以下载或查看,没有账号?开始注册
x
time 模块[backcolor=rgb(245, 245, 245) !important][url=][/url]
7 Y8 p2 f, u: d. l J' a. J8 b 1 1 >>> import time 2 2 >>> time.time() 3 3 1491064723.808669 4 4 >>> # time.time()返回当前时间的时间戳timestamp(定义为从格林威治时间1970年01月01日00时00分00秒起至现在的总秒数)的方法,无参数 5 5 >>> time.asctime() 6 6 'Sun Apr 2 00:39:32 2017' 7 7 >>> # time.asctime()把struct_time对象格式转换为字符串格式为'Sun Apr 2 00:39:32 2017' 8 8 >>> time.asctime(time.gmtime()) 9 9 'Sat Apr 1 16:41:41 2017'10 10 >>> time.asctime(time.localtime())11 11 'Sun Apr 2 00:42:06 2017'12 12 >>> time.ctime()13 13 'Sun Apr 2 00:42:29 2017'14 14 >>> # time.ctime()把时间戳转换为字符串格式'Sun Apr 2 00:42:29 2017',默认为当前时间戳15 15 >>> time.ctime(1491064723.808669)16 16 'Sun Apr 2 00:38:43 2017'17 17 >>> time.altzone # 返回与utc时间的时间差,以秒计算18 18 -3240019 19 >>> time.localtime() # 把时间戳转换为struct_time对象格式,默认返回当前时间戳20 20 time.struct_time(tm_year=2017, tm_mon=4, tm_mday=2, tm_hour=0, tm_min=45, tm_sec=26, tm_wday=6, tm_yday=92, tm_isdst=0)21 21 >>> time.localtime(1491064723.808669)22 22 time.struct_time(tm_year=2017, tm_mon=4, tm_mday=2, tm_hour=0, tm_min=38, tm_sec=43, tm_wday=6, tm_yday=92, tm_isdst=0)23 23 >>> 24 24 >>> time.gmtime() # 将utc时间戳转换成struct_time对象格式,默认返回当前时间的25 25 time.struct_time(tm_year=2017, tm_mon=4, tm_mday=1, tm_hour=16, tm_min=46, tm_sec=32, tm_wday=5, tm_yday=91, tm_isdst=0)26 26 >>> time.gmtime(1491064723.808669)27 27 time.struct_time(tm_year=2017, tm_mon=4, tm_mday=1, tm_hour=16, tm_min=38, tm_sec=43, tm_wday=5, tm_yday=91, tm_isdst=0)28 28 >>> 29 29 >>> 30 30 >>> time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) # 将本地时间的struct_time格式转成自定义字符串格式 2017-04-01 23:15:4731 31 '2017-04-02 00:47:49'32 32 >>> 33 33 >>> time.strftime('%Y-%m-%d %H:%M:%S', time.gmtime()) # 将utc时间的struct_time格式转成自定义字符串格式 2017-04-01 23:15:4734 34 '2017-04-01 16:48:27'35 35 >>> 36 36 >>> time.strptime('2017-04-02 00:47:49', '%Y-%m-%d %H:%M:%S') # 将 日期字符串 转成 struct_time时间对象格式,注意转换后的tm_isdst=-1()夏令时状态37 37 time.struct_time(tm_year=2017, tm_mon=4, tm_mday=2, tm_hour=0, tm_min=47, tm_sec=49, tm_wday=6, tm_yday=92, tm_isdst=-1)38 38 >>> 39 39 >>> time.mktime(time.localtime())40 40 1491065416.041 41 >>> # 将struct_tiame时间对象转成时间戳 结果返回1491061855.0 ,忽略小于秒的时间(忽略小数点后面)42 42 >>> 43 43 >>> time.mktime(time.localtime(1491061855.0011407))44 44 1491061855.045 45 >>> # 结果返回1491061855.0 ,忽略小于秒的时间(忽略小数点后面)46 46 >>> 47 47 >>> time.mktime(time.gmtime(1491061855.0011407))48 48 1491033055.049 49 >>> 50 50 >>> # 结果返回1491033055.0 ,忽略小于秒的时间(忽略小数点后面)51 51 >>> [backcolor=rgb(245, 245, 245) !important][url=][/url]
) j7 G- _# R0 ?, n0 \
& N" P: l2 R+ R- B' {时间转换关系图 格式字符及意义 %a 星期的简写。如 星期三为Web5 A! Z1 I7 S0 V0 A! i# x1 L# W
%A 星期的全写。如 星期三为Wednesday. L, k3 S& G, i7 c- B
%b 月份的简写。如4月份为Apr
% r% ~4 s V, O8 }- l: l/ w%B月份的全写。如4月份为April # N# Y g0 T5 E" Q$ S& \: j" \
%c: 日期时间的字符串表示。(如: 04/07/10 10:43:39). j% D; B) T& ~) F) f' y' C
%d: 日在这个月中的天数(是这个月的第几天)
. ^4 e3 Y1 {# k* a%f: 微秒(范围[0,999999])
9 \* y' U! I C2 o%H: 小时(24小时制,[0, 23])
; d" H w _& F5 i& K%I: 小时(12小时制,[0, 11])
6 C. V% L( z" F%j: 日在年中的天数 [001,366](是当年的第几天)
" g6 a5 P% h L4 A6 M%m: 月份([01,12])
9 [! R6 A7 u7 R* [& U6 v0 N%M: 分钟([00,59])
( v. R: H4 }3 {8 w2 d4 L% h4 f* A%p: AM或者PM
# T$ o4 v" o E: b: _%S: 秒(范围为[00,61],为什么不是[00, 59],参考python手册~_~)
4 _6 f& X* ~, j/ P e* [- y%U: 周在当年的周数当年的第几周),星期天作为周的第一天
8 F7 t7 T9 u7 F; C. m%w: 今天在这周的天数,范围为[0, 6],6表示星期天
/ T) \% Y# K* l8 o%W: 周在当年的周数(是当年的第几周),星期一作为周的第一天& f2 X9 u6 l# Z' l$ e
%x: 日期字符串(如:04/07/10)' z5 y, k$ J- E! |: ^
%X: 时间字符串(如:10:43:39)
6 |0 O3 V0 X6 B) O/ U9 ]7 N1 x%y: 2个数字表示的年份2 Q% H6 E9 z% w6 p
%Y: 4个数字表示的年份
% {7 ~. \! H7 }1 V, y+ Z. [5 k# \$ W%z: 与utc时间的间隔 (如果是本地时间,返回空字符串)# A8 S8 q/ a! P9 G" [
%Z: 时区名称(如果是本地时间,返回空字符串) datetime模块,方便时间计算 [backcolor=rgb(245, 245, 245) !important][url=][/url]
- U/ f/ L4 |7 U a( q- M$ V' H 1 >>> import datetime 2 >>> datetime.datetime.now() 3 datetime.datetime(2017, 4, 7, 16, 52, 3, 199458) 4 # 返回一组数据(年,月,日,小时,分钟,秒,微秒) 5 6 >>> print(datetime.datetime.now()) 7 2017-04-07 16:52:55.000164 8 # 打印返回格式(固定) 9 10 >>> datetime.datetime.now()+datetime.timedelta(days=3)11 datetime.datetime(2017, 4, 10, 16, 53, 51, 180847)12 # 时间加(减),可以是日,秒,微秒,毫秒,分,小时,周13 #days=0, seconds=0, microseconds=0,milliseconds=0, minutes=0, hours=0, weeks=014 >>> print(datetime.datetime.now()+datetime.timedelta(weeks=1))15 2017-04-17 16:54:08.91624316 17 >>> datetime.datetime.now().replace(minute=3,hour=2)18 datetime.datetime(2017, 4, 7, 2, 3, 11, 163663)19 # 时间替换20 21 >>> datetime.datetime.now()22 datetime.datetime(2017, 4, 7, 16, 58, 22, 195439)23 24 >>> datetime.datetime.now().replace(day=1,month=1)25 datetime.datetime(2017, 1, 1, 16, 59, 13, 210556)26 >>> 27 # 直接替换相应位置数据[backcolor=rgb(245, 245, 245) !important][url=][/url]
( ^3 m% {2 \; d; C' v7 ]# X% i' U H2 `
random模块[backcolor=rgb(245, 245, 245) !important][url=][/url]
3 u% ]' ]0 H0 x1 i& H$ B 1 import random 2 >>> print(random.random()) 3 0.5364503211492734 4 >>> print(random.randint(1,10)) 5 3 6 >>> # 整数1-10(包括10),随机取一个值 7 >>> 8 >>> 9 >>> 10 >>> print(random.randrange(1, 10))11 812 >>> # 整数1-10(不包括10),随机取一个值[backcolor=rgb(245, 245, 245) !important][url=][/url]$ L* B8 Z& \, x7 }7 Q
! `& S8 c" @* T0 T& L# F! v# p! n生成随机验证码 [backcolor=rgb(245, 245, 245) !important][url=][/url]' Y4 G3 ~* v( T; q1 v; t
1 import random 2 3 checkcode = '' 4 for i in range(6): 5 current = random.randrange(0, 6) 6 if current != i and current+1 != i: 7 temp = chr(random.randint(65, 90)) 8 # 65-90是A-Z 9 elif current+1 == i:10 temp = chr(random.randint(97, 122))11 # 97-122是a-z12 else:13 temp = random.randint(0, 9)14 checkcode += str(temp)15 print(checkcode)16 17 # 一共6位验证码,18 # 第一位有1/6几率是数字,其它都是大写字母19 # 第二到第六位,都是有1/6几率是小写字母,1/6几率是数字,其它都是大写字母[backcolor=rgb(245, 245, 245) !important][url=][/url]
' Q/ N& x$ Z( `7 i
' ^ q; S- Q6 s$ I o* }: l @" q0 ~OS模块 提供对操作系统进行调用的接口 [backcolor=rgb(245, 245, 245) !important][url=][/url]
* b O' G, E+ L2 B" Y) Q8 ` 1 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 2 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd 3 os.curdir 返回当前目录: ('.') 4 os.pardir 获取当前目录的父目录字符串名:('..') 5 os.makedirs('dirname1/dirname2') 可生成多层递归目录 6 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 7 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname 8 os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname 9 os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印10 os.remove() 删除一个文件11 os.rename("oldname","newname") 重命名文件/目录12 os.stat('path/filename') 获取文件/目录信息13 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"14 os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"15 os.pathsep 输出用于分割文件路径的字符串16 os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'17 os.system("bash command") 运行shell命令,直接显示18 os.environ 获取系统环境变量19 os.path.abspath(path) 返回path规范化的绝对路径20 os.path.split(path) 将path分割成目录和文件名二元组返回21 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素22 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素23 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False24 os.path.isabs(path) 如果path是绝对路径,返回True25 os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False26 os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False27 os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略28 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间29 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间[backcolor=rgb(245, 245, 245) !important][url=][/url]! A* J; d; _# x- A# S( Y; |
, q$ ]! o' P0 z4 |1 c9 Csys模块用于提供对解释器相关的操作 [backcolor=rgb(245, 245, 245) !important][url=][/url] k w% e" U& G* K% B2 d3 C
1 sys.argv 命令行参数List,第一个元素是程序本身路径2 sys.exit(n) 退出程序,正常退出时exit(0)3 sys.version 获取Python解释程序的版本信息4 sys.maxint 最大的Int值5 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值6 sys.platform 返回操作系统平台名称7 sys.stdout.write('please:')8 val = sys.stdin.readline()[:-1][backcolor=rgb(245, 245, 245) !important][url=][/url]5 V r" c6 j" b: Q" d9 X6 T, a. O+ X6 _
# {) X' _7 ]; F8 n2 Yshutil 模块 高级的 文件、文件夹、压缩包 处理模块 shutil.copyfileobj(fsrc, fdst)
8 Q, l# g9 n/ _1 D将文件内容拷贝到另一个文件中,可以部分内容,如下(注意需要打开文件): 1 import shutil2 3 with open('testfile', 'r', encoding='utf-8') as f,\4 open('testfile1', 'w', encoding='utf-8') as f1:5 shutil.copyfileobj(f, f1)
$ w7 f9 I/ B S5 o2 t/ I8 Z" t& F* A: H+ g
shutil.copyfile(src, dst)
6 b# h3 c+ p4 g X仅拷贝文件 用法是shutil.copyfile(src_path, dst_path),如下: import shutilshutil.copyfile(r'C:\Users\笔记.txt', r'C:\test1\笔记.txt')6 t8 a" A7 k m+ ?! g" ]* i- _& G: `
shutil.copystat(src, dst)4 |" [: {# X# L! a) ^
仅拷贝状态信息,包括:mode bits, atime, mtime, flags.用法格式同shutil.copyfile(src, dst) shutil.copymode(src, dst)* X! k3 O+ M8 ^! [) Y; W, Q9 s% ~
仅拷贝权限。内容、组、用户均不变,用法格式同shutil.copyfile(src, dst) shutil.copy(src, dst)6 o& h0 i! |4 C$ p( t
拷贝文件和权限,用法个是同shutil.copyfile(src, dst) shutil.copy2(src, dst)
: ~$ C* R7 \5 \' s" h' k拷贝文件和状态信息,用法个是同shutil.copyfile(src, dst) shutil.copytree(src, dst, symlinks=False, ignore=None)
1 q) W4 u/ [. F* D( x* ^拷贝一个目录,src是原目录路径,dst是新目录路径 shutil.rmtree(path), ^3 g: H! l1 K( l& y
删除一个目录,path为目录路径 & _- q8 Z7 B& |: \% l6 D
shutil.move(src, dst)+ d' F1 a; t* q. B7 s
移动文件或目录,src是原文件或目录的路径,dst是新目录路径!使用的copy2函数拷贝文件和状态信息 1 import shutil2 3 shutil.move(r'C:\Users\笔记.txt', r'C:\test1')
9 W3 K+ b/ d" `
, Q* s8 {" |( }. d4 A: j3 {shutil.make_archive(base_name, format,...) 创建压缩包并返回文件路径,例如:zip、tar - base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,3 h: b- Q2 D# C8 x! [
如:www =>保存至当前路径6 N2 e: C. X0 E* Z
如:/Users/wupeiqi/www =>保存至/Users/wupeiqi/ - format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要压缩的文件夹路径(默认当前目录)
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是logging.Logger对象5 K7 m' w1 F6 J' n. Z! T% j% H
[backcolor=rgb(245, 245, 245) !important][url=][/url]$ Q. ]( a6 i9 g9 f+ V+ n
1 #将 /Users/wupeiqi/Downloads/test 下的文件打包放置当前程序目录2 3 import shutil4 ret = shutil.make_archive("wwwwwwwwww", 'gztar', root_dir='/Users/wupeiqi/Downloads/test')5 6 7 #将 /Users/wupeiqi/Downloads/test 下的文件打包放置 /Users/wupeiqi/目录8 import shutil9 ret = shutil.make_archive("/Users/wupeiqi/wwwwwwwwww", 'gztar', root_dir='/Users/wupeiqi/Downloads/test')[backcolor=rgb(245, 245, 245) !important][url=][/url]
; ]" |2 x# u3 z
# e) s0 k8 j5 ashutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细: zipfile 压缩解压
1 n) |9 J7 f) _, n W2 y# N8 o0 I9 d9 O2 p9 w, \9 r
tarfile只打包不压缩,zip会压缩 logging 模块 用于便捷记录日志且线程安全的模块 [backcolor=rgb(245, 245, 245) !important][url=][/url]$ M5 a# W8 J/ t4 `- I
1 import logging 2 3 4 logging.basicConfig(filename= 'log.log', 5 format= '%(asctime)s %(filename)s : %(lineno)s -%(levelname)s : %(message)s', 6 datefmt= '%m-%d-%Y %I:%M:%S %p', 7 level=10 ) 8 9 logging.debug( 'debug')10 logging.info( 'info')11 logging.warning( 'warning')12 logging.error( 'error')13 logging.critical( 'critical')14 logging.log(10, 'log') [backcolor=rgb(245, 245, 245) !important][url=][/url]! O8 t6 ?' l7 Z
8 p+ p1 R4 v5 k$ T& |
对于等级level CRITICAL level= 50FATAL level= 50+ U- i9 _- O: W
ERROR level= 405 r3 X9 Y3 M0 Q; ?; Y
WARNING level= 30
' Y5 h4 z4 |2 o; Y( @WARN level= 303 |" C: I' V+ F; Y3 W b" V2 u. Q
INFO level= 20" A9 F" w3 g+ Q% r& x
DEBUG level= 10
) q/ j3 ]; v$ bNOTSET level= 0
5 ]: E# Z# z# ?4 V2 }; \只有大于当前日志等级的操作才会被记录!!!
0 ^! {) _& \& Y1 n: A6 b
0 p: M/ S1 y1 Y: X5 m . l/ w5 j! S0 c- ~! H- e7 Y
日志格式 %(name)s | Logger的名字 | %(levelno)s | 数字形式的日志级别 | %(levelname)s | 文本形式的日志级别 | %(pathname)s | 调用日志输出函数的模块的完整路径名,可能没有 | %(filename)s | 调用日志输出函数的模块的文件名 | %(module)s | 调用日志输出函数的模块名 | %(funcName)s | 调用日志输出函数的函数名 | %(lineno)d | 调用日志输出函数的语句所在的代码行 | %(created)f | 当前时间,用UNIX标准的表示时间的浮 点数表示 | %(relativeCreated)d | 输出日志信息时的,自Logger创建以 来的毫秒数 | %(asctime)s | 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 | %(thread)d | 线程ID。可能没有 | %(threadName)s | 线程名。可能没有 | %(process)d | 进程ID。可能没有 | %(message)s | 用户输出的消息 |
% X0 U" R% w0 T9 a0 W0 [! e: Z8 e如果想同时把log打印在屏幕和文件日志里,就需要了解一点复杂的知识 了
# R3 m8 z d8 s, c+ {3 MPython 使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适:
logger提供了应用程序可以直接使用的接口; handler将(logger创建的)日志记录发送到合适的目的输出; filter提供了细度设备来决定输出哪条日志记录; formatter决定日志记录的最终输出格式。 logger( ?: P2 h# j; N- E. Y
每个程序在输出信息之前都要获得一个Logger。Logger通常对应了程序的模块名,比如聊天工具的图形界面模块可以这样获得它的Logger:
) X P: h: x" G O0 }6 _LOG=logging.getLogger(”chat.gui”)
. J% O; N) \, U8 V' [6 d, g而核心模块可以这样:
; Z# P5 f; G$ G( R1 uLOG=logging.getLogger(”chat.kernel”) Logger.setLevel(lel):指定最低的日志级别,低于lel的级别将被忽略。debug是最低的内置级别,critical为最高
! q& a& D$ E% o! Q, x" \Logger.addFilter(filt)、Logger.removeFilter(filt):添加或删除指定的filter
( C4 o3 P' n% g! K$ _0 a& Y" ILogger.addHandler(hdlr)、Logger.removeHandler(hdlr):增加或删除指定的handler5 o: |% z' M. J. n7 @
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical():可以设置的日志级别 handler handler对象负责发送相关的信息到指定目的地。Python的日志系统有多种Handler可以使用。有些Handler可以把信息输出到控制台,有些Logger可以把信息输出到文件,还有些 Handler可以把信息发送到网络上。如果觉得不够用,还可以编写自己的Handler。可以通过addHandler()方法添加多个多handler* ~/ J M" {# u7 K/ R- r" g8 G$ w
Handler.setLevel(lel):指定被处理的信息级别,低于lel级别的信息将被忽略# c. i, l( ~$ y) h' B% r% s
Handler.setFormatter():给这个handler选择一个格式
& ~6 a5 T4 G9 _! u8 ^2 eHandler.addFilter(filt)、Handler.removeFilter(filt):新增或删除一个filter对象 / T' q3 d* u4 [
每个Logger可以附加多个Handler。接下来我们就来介绍一些常用的Handler:
9 a* k) ]+ i, W* ?4 b; R1) logging.StreamHandler4 m0 G$ r$ R5 Q4 }8 x- q3 M
使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。它的构造函数是:' O* k! k( Y4 U% C
StreamHandler([strm])$ ]4 C" H* c4 j2 v" K
其中strm参数是一个文件对象。默认是sys.stderr 9 G8 L, p9 q, X
2) logging.FileHandler$ F2 I/ D1 {; ?
和StreamHandler类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件。它的构造函数是:
% h' _1 K- I7 t9 {5 z9 l4 \; hFileHandler(filename[,mode])' o0 }. T& c* }1 [# M
filename是文件名,必须指定一个文件名。
# t% L3 R, v- F: `5 G1 smode是文件的打开方式。参见Python内置函数open()的用法。默认是’a',即添加到文件末尾。 3) logging.handlers.RotatingFileHandler
! x$ D* O' X5 A$ B1 d5 m这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。它的构造函数是:* U: o5 f. |# x5 N m4 b/ i0 V
RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]])
. F# x* I9 f6 [- b/ W3 C; Q3 Y其中filename和mode两个参数和FileHandler一样。0 o1 Y* Y. N6 c! g0 L
maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。- m3 m2 o& B( @$ x. k
backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。
9 a {! {6 A e4) logging.handlers.TimedRotatingFileHandler
3 e6 Y* `0 b5 e# \$ Z这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。它的构造函数是:
% K6 R" K% e0 y6 t M1 PTimedRotatingFileHandler( filename [,when [,interval [,backupCount]]])
: P" {' Q$ r# h. D7 o, \2 u! X其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。! d9 q; p \9 a# ~
interval是时间间隔。
d! y1 v5 y U) s/ Y* S) O. Ewhen参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:
, j3 r# f1 ?1 c) E0 ]& GS 秒; ^2 F$ x8 T {3 S
M 分1 I1 r: |! e+ ]+ b
H 小时; v( e. b+ E. g* T, t# c4 m" L
D 天
% J7 \' F' Z0 `" u3 P$ M4 x4 v: O; wW 每星期(interval==0时代表星期一)( h( r6 V7 ^+ @ @, a& C8 v: o: h
midnight 每天凌晨
3 v8 n+ p9 _4 S
re模块正则表达式使用反斜杆(\)来转义特殊字符,使其可以匹配字符本身,而不是指定其他特殊的含义。这可能会和python字面意义上的字符串转义相冲突,这也许有些令人费解。比如,要匹配一个反斜杆本身,你也许要用'\\\\'来做为正则表达式的字符串,因为正则表达式要是\\,而字符串里,每个反斜杆都要写成\\。 你也可以在字符串前加上 r 这个前缀来避免部分疑惑,因为 r 开头的python字符串是 raw 字符串,所以里面的所有字符都不会被转义,比如r'\n'这个字符串就是一个反斜杆加上一字母n,而'\n'我们知道这是个换行符。因此,上面的'\\\\'你也可以写成r'\\',这样,应该就好理解很多了。可以看下面这段 [backcolor=rgb(245, 245, 245) !important][url=][/url]
, `8 n' Z5 u% _ 1 >>> import re 2 >>> s = '\x5c' 3 >>> print(s) 4 \ 5 >>> re.match('\\\\', s) #这样可以匹配 6 <_sre.SRE_Match object; span=(0, 1), match='\\'> 7 >>> re.match(r'\\', s) #这样也可以 8 <_sre.SRE_Match object; span=(0, 1), match='\\'> 9 >>> re.match('\\', s) #但是这样不行10 Traceback (most recent call last):11 File "<pyshell#5>", line 1, in <module>12 re.match('\\', s) #但是这样不行13 File "C:\Python36\lib\re.py", line 172, in match14 return _compile(pattern, flags).match(string)15 File "C:\Python36\lib\re.py", line 301, in _compile16 p = sre_compile.compile(pattern, flags)17 File "C:\Python36\lib\sre_compile.py", line 562, in compile18 p = sre_parse.parse(p, flags)19 File "C:\Python36\lib\sre_parse.py", line 848, in parse20 source = Tokenizer(str)21 File "C:\Python36\lib\sre_parse.py", line 231, in __init__22 self.__next()23 File "C:\Python36\lib\sre_parse.py", line 245, in __next24 self.string, len(self.string) - 1) from None25 sre_constants.error: bad escape (end of pattern) at position 026 >>> [backcolor=rgb(245, 245, 245) !important][url=][/url]
/ \7 Q8 T3 t, |' q* T2 |
1 ?6 X5 ?4 k. |& S7 i' E4 \, p. I; M
- S9 t: \/ i/ v2 K正则表达式语法 正则表达式(RE)指定一个与之匹配的字符集合;本模块所提供的函数,将可以用来检查所给的字符串是否与指定的正则表达式匹配。
" B4 E& i! {% q" b. g$ v正则表达式可以被连接,从而形成新的正则表达式;例如A和B都是正则表达式,那么AB也是正则表达式。一般地,如果字符串p与A匹配,q与B匹配的话,那么字符串pq也会与AB匹配,但A或者B里含有边界限定条件或者命名组操作的情况除外。也就是说,复杂的正则表达式可以用简单的连接而成。- n: ~* v0 R3 z4 h) z0 }
正则表达式可以包含特殊字符和普通字符,大部分字符比如'A','a'和'0'都是普通字符,如果做为正则表达式,它们将匹配它们本身。由于正则表达式可以连接,所以连接多个普通字符而成的正则表达式last也将匹配'last'。(后面将用不带引号的表示正则表达式,带引号的表示字符串) 下面就来介绍正则表达式的特殊字符: '.'
% r/ u2 i. F& d( i" @点号,在普通模式,它匹配除换行符外的任意一个字符;如果指定了 DOTALL 标记,匹配包括换行符以内的任意一个字符。 '^'1 f" k$ x5 d7 Z. Q/ o$ l
尖尖号,匹配一个字符串的开始,在 MULTILINE 模式下,也将匹配任意一个新行的开始。 '$': S3 _% ?; Y7 h
美元符号,匹配一个字符串的结尾或者字符串最后面的换行符,在 MULTILINE 模式下,也匹配任意一行的行尾。也就是说,普通模式下,foo.$去搜索'foo1\nfoo2\n'只会找到'foo2′,但是在 MULTILINE 模式,还能找到 ‘foo1′,而且就用一个 $ 去搜索'foo\n'的话,会找到两个空的匹配:一个是最后的换行符,一个是字符串的结尾,演示: [backcolor=rgb(245, 245, 245) !important][url=][/url]- e& F. `: ^( ~' \
1 >>> re.findall('(foo.$)', 'foo1\nfoo2\n')2 ['foo2'3 >>> re.findall('(foo.$)', 'foo1\nfoo2\n', re.MULTILINE)4 ['foo1', 'foo2'5 >>> re.findall('($)', 'foo\n')6 ['', ''7 >>> [backcolor=rgb(245, 245, 245) !important][url=][/url]* f: A Q. D$ w( V# N4 B) D; o
& q* [7 `$ ?- j/ L7 h6 k'*'3 U1 ~6 r9 A$ l: _& B
星号,指定将前面的RE重复0次或者任意多次,而且总是试图尽量多次地匹配。 '+'
0 ^: L. _4 T5 ]# x1 I( c加号,指定将前面的RE重复1次或者任意多次,而且总是试图尽量多次地匹配。 '?', I( H5 e7 c ]+ B" G8 S- B
问号,指定将前面的RE重复0次或者1次,如果有的话,也尽量匹配1次。 *?, +?, ??
; K5 ?* L: L7 E' d: Q% m1 y从前面的描述可以看到'*','+'和'?'都是贪婪的,但这也许并不是我们说要的,所以,可以在后面加个问号,将策略改为非贪婪,只匹配尽量少的RE。示例,体会两者的区别: 1 >>> re.findall('<(.*)>', '<H1>title</H1>')2 ['H1>title</H1'3 >>> re.findall('<(.*?)>', '<H1>title</H1>')4 ['H1', '/H1']1 Z( s- ^& G$ J! ^2 m$ j5 h
{m,n}
9 C, D" ~* ^, k' m! vm和n都是数字,指定将前面的RE重复m到n次,例如a{3,5}匹配3到5个连续的a。注意,如果省略m,将匹配0到n个前面的RE;如果省略n,将匹配n到无穷多个前面的RE;当然中间的逗号是不能省略的,不然就变成前面那种形式了。 {m,n}?
7 _: `) }7 O) V) g0 q8 b前面说的{m,n},也是贪婪的,a{3,5}如果有5个以上连续a的话,会匹配5个,这个也可以通过加问号改变。a{3,5}?如果可能的话,将只匹配3个a。 '\'
4 z Y9 }) Z5 b, p反斜杆,转义'*','?'等特殊字符,或者指定一个特殊序列(下面会详述)
* _# @# b0 u F/ B: x9 U由于之前所述的原因,强烈建议用raw字符串来表述正则。 []
1 L7 P, r8 S( i方括号,用于指定一个字符的集合。可以单独列出字符,也可以用'-'连接起止字符以表示一个范围。特殊字符在中括号里将失效,比如[akm$]就表示字符'a','k','m',或'$',在这里$也变身为普通字符了。[a-z]匹配任意一个小写字母,[a-zA-Z0-9]匹配任意一个字母或数字。如果你要匹配']'或'-'本身,你需要加反斜杆转义,或者是将其置于中括号的最前面,比如[]]可以匹配']'
6 V! s# |, f* p% m Z- }9 a你还可以对一个字符集合取反,以匹配任意不在这个字符集合里的字符,取反操作用一个'^'放在集合的最前面表示,放在其他地方的'^'将不会起特殊作用。例如[^5]将匹配任意不是'5'的字符;[^^]将匹配任意不是'^'的字符。
/ C' V- U2 v' j注意:在中括号里,+、*、(、)这类字符将会失去特殊含义,仅作为普通字符。反向引用也不能在中括号内使用。 '|'3 ^2 y" F J [: N' u5 e9 `# j
管道符号,A和B是任意的RE,那么A|B就是匹配A或者B的一个新的RE。任意个数的RE都可以像这样用管道符号间隔连接起来。这种形式可以被用于组中(后面将详述)。对于目标字符串,被'|'分割的RE将自左至右一一被测试,一旦有一个测试成功,后面的将不再被测试,即使后面的RE可能可以匹配更长的串,换句话说,'|'操作符是非贪婪的。要匹配字面意义上的'|',可以用反斜杆转义:\|,或是包含在反括号内:[|]。 (...)
2 S" q/ b8 g/ K. m) c5 N匹配圆括号里的RE匹配的内容,并指定组的开始和结束位置。组里面的内容可以被提取,也可以采用\number这样的特殊序列,被用于后续的匹配。要匹配字面意义上的'('和')',可以用反斜杆转义:\(、\),或是包含在反括号内:[(]、[)]。 (?...)
0 D0 o6 L* |$ `% P# ~这是一个表达式的扩展符号。'?'后的第一个字母决定了整个表达式的语法和含义,除了(?P...)以外,表达式不会产生一个新的组。下面介绍几个目前已被支持的扩展: (?iLmsux)
5 Z# O H k p: L5 k9 B+ c" w'i'、'L'、'm'、's'、'u'、'x'里的一个或多个字母。表达式不匹配任何字符,但是指定相应的标志:re.I(忽略大小写)、re.L(依赖locale)、re.M(多行模式)、re.S(.匹配所有字符)、re.U(依赖Unicode)、re.X(详细模式)。关于各个模式的区别,下面会有专门的一节来介绍的。使用这个语法可以代替在re.compile()的时候或者调用的时候指定flag参数。/ C' b5 u0 ]4 x' l
例如,上面举过的例子,可以改写成这样(和指定了re.MULTILINE是一样的效果): 1 >>> re.findall('(?m)(foo.$)', 'foo1\nfoo2\n')2 ['foo1', 'foo2'3 >>> re.findall('(foo.$)', 'foo1\nfoo2\n', re.MULTILINE)4 ['foo1', 'foo2'5 >>>
6 H- i" n, ^* I" a, T/ r0 Q; a另外,还要注意(?x)标志如果有的话,要放在最前面。
% V" e- [! Q9 ~1 S, v(?:...)
& m! H5 n1 W$ n2 {6 k匹配内部的RE所匹配的内容,但是不建立组。 (?P<name>...)1 T8 z( {) |) P3 e$ a
和普通的圆括号类似,但是子串匹配到的内容将可以用命名的name参数来提取。组的name必须是有效的python标识符,而且在本表达式内不重名。命名了的组和普通组一样,也用数字来提取,也就是说名字只是个额外的属性。
6 V0 r" B" d3 d) U, w4 a' M演示一下: 1 >>> m=re.match('(?P<var>[a-zA-Z_]\w*)', 'abc=123')2 >>> m.group('var')3 'abc'4 >>> m.group(1)5 'abc'6 >>> / N/ r8 O$ J3 G8 z2 i
匹配之前以name命名的组里的内容。
# d5 c& v2 w! v8 j% x8 o演示一下: 1 >>> re.match('<(?P<tagname>\w*)>.*</(?P=tagname)>', '<h1>xxx</h2>') #这个不匹配2 >>> re.match('<(?P<tagname>\w*)>.*</(?P=tagname)>', '<h1>xxx</h1>') #这个匹配3 <_sre.SRE_Match object; span=(0, 12), match='<h1>xxx</h1>'>4 >>> $ F/ z5 K |% y) ]! i
(?#...)4 [+ x/ @. |" J) m7 D i' _( @* E
注释,圆括号里的内容会被忽略。 (?=...)
/ C2 Y8 a- R9 c: `% q& C# @如果 ... 匹配接下来的字符,才算匹配,但是并不会消耗任何被匹配的字符。例如 Isaac (?=Asimov) 只会匹配后面跟着 'Asimov' 的 'Isaac ',这个叫做“前瞻断言”。 (?!...)
7 T' J* _9 ?6 S! _和上面的相反,只匹配接下来的字符串不匹配 ... 的串,这叫做“反前瞻断言”。 (?<=...)
7 t$ l* p: w/ r2 v1 x7 W5 V# A只有当当前位置之前的字符串匹配 ... ,整个匹配才有效,这叫“后顾断言”。字符串'abcdef'可以匹配正则(?<=abc)def,因为会后向查找3个字符,看是否为abc。所以内置的子RE,需要是固定长度的,比如可以是abc、a|b,但不能是a*、a{3,4}。注意这种RE永远不会匹配到字符串的开头。举个例子,找到连字符('-')后的单词: 1 >>> m = re.search('(?<=-)\w+', 'spam-egg')2 >>> m.group(0)3 'egg'
' O5 O' M5 X1 F. h(?<!...)
/ K" X7 Z5 O5 x7 j0 D; a/ ^同理,这个叫做“反后顾断言”,子RE需要固定长度的,含义是前面的字符串不匹配 ... 整个才算匹配。 1 s1 b- E2 n( j3 A
(?(id/name)yes-pattern|no-pattern)
4 M- h$ U' t9 P5 N: g: Q% w如有由id或者name指定的组存在的话,将会匹配yes-pattern,否则将会匹配no-pattern,通常情况下no-pattern也可以省略。例如:(<)?(\w+@\w+(?:\.\w+)+)(?(1)>)可以匹配 '<user@host.com>' 和 'user@host.com',但是不会匹配 '<user@host.com'。 下面列出以'\'开头的特殊序列。如果某个字符没有在下面列出,那么RE的结果会只匹配那个字母本身,比如,\$只匹配字面意义上的'$'。 字符: . 匹配除换行符以外的任意字符) N$ t3 D! D9 x% B
\w 匹配字母或数字或下划线或汉字2 Y! C! _+ k+ P# m
\s 匹配任意的空白符
% h2 F* {2 b9 n' b+ T5 @ \d 匹配数字
5 p; J+ |: s) @3 U$ C \b 匹配单词的开始或结束$ M S- z' d: P9 n ~
^ 匹配字符串的开始
5 ?) Y+ K, ]5 W ]) F8 P $ 匹配字符串的结束 h& z- a4 m6 B' G& ~ o
次数:
: ` @$ G. p$ Y( f; P1 @/ S. J * 重复零次或更多次3 w. j9 @" B7 g4 p( J* T$ ~
+ 重复一次或更多次' Q- i5 m$ U' ]( K% e
? 重复零次或一次
$ G% [: f/ }9 U1 C" [' Y- P {n} 重复n次
+ T- p i7 o, {, h' g {n,} 重复n次或更多次
Y2 S; Z' d- Q& F3 a4 \ {n,m} 重复n到m次 # E4 v* c& c" f z7 \8 T
匹配之搜索 python提供了两种基于正则表达式的操作:匹配(match)从字符串的开始检查字符串是否个正则匹配。而搜索(search)检查字符串任意位置是否有匹配的子串(perl默认就是如此)。
) {% w% n, C' R6 l- f. Y6 ~注意,即使search的正则以'^'开头,match和search也还是有许多不同的。 1 >>> re.match("c", "abcdef") # 不匹配2 >>> re.search("c", "abcdef") # 匹配3 <_sre.SRE_Match object at ...>
( {, _5 E6 R" m( m
7 w3 w4 {! B+ e X7 @9 r模块的属性和方法 0 L5 F* w" d8 }& D# `' i
re.compile(pattern[, flags])2 G( K% D' Z J$ i" Y7 A
把一个正则表达式pattern编译成正则对象,以便可以用正则对象的match和search方法。
6 l9 @! M$ ?. I% r得到的正则对象的行为(也就是模式)可以用flags来指定,值可以由几个下面的值OR得到。8 x H1 q" W n' G9 C& q6 u# T
以下两段内容在语法上是等效的: prog = re.compile(pattern)result = prog.match(string)
7 y' O3 L; |) cresult = re.match(pattern, string)
/ O, |1 G( _* |4 d; Y区别是,用了re.compile以后,正则对象会得到保留,这样在需要多次运用这个正则对象的时候,效率会有较大的提升。再用上面用过的例子来演示一下,用相同的正则匹配相同的字符串,执行100万次,就体现出compile的效率了(数据来自我的台式电脑英特尔 Core i5-6500 @ 3.20GHz 四核): [backcolor=rgb(245, 245, 245) !important][url=][/url]
# H1 O) M& |+ B0 U( A4 A; u) n>>> import timeit>>> timeit.timeit( setup="import re; reg = re.compile('<(?P<tagname>\w*)>.*</(?P=tagname)>')", stmt="reg.match('<h1>xxx</h1>')", number=1000000)0.3993007156773078>>> timeit.timeit( setup='import re', stmt="re.match('<(?P<tagname>\w*)>.*</(?P=tagname)>', '<h1>xxx</h1>')", number=1000000)0.8457147421697897>>>[backcolor=rgb(245, 245, 245) !important][url=][/url]
% A+ }& T2 O9 ]4 v7 l3 r# J; w, _1 W. U' k. W( Q6 _
/ t) B( f; U% g
re.I
9 |0 Z- E2 Q1 D) X! I4 E4 Sre.IGNORECASE
7 }7 ^4 c3 _% t# I& Y
' Q$ a1 @, M$ S/ f8 z9 N, N/ O让正则表达式忽略大小写,这样一来,[A-Z]也可以匹配小写字母了。此特性和locale无关。 7 a g. q# [9 A i3 q
re.L
6 K9 }) j5 i4 S8 Z0 Qre.LOCALE
1 y2 T1 g- o9 O6 W. N7 B8 B) o让\w、\W、\b、\B、\s和\S依赖当前的locale。 re.M
, G6 j; E1 W( n, O" zre.MULTILINE& o3 @* b. N& i' [ A
影响'^'和'$'的行为,指定了以后,'^'会增加匹配每行的开始(也就是换行符后的位置);'$'会增加匹配每行的结束(也就是换行符前的位置)。 re.S
! d4 P* w' o/ P" j$ T; are.DOTALL
3 f- O8 ^) i$ x! j影响'.'的行为,平时'.'匹配除换行符以外的所有字符,指定了本标志以后,也可以匹配换行符。 re.U) k4 X% o& d% d* k2 ?8 |
re.UNICODE
6 \9 ?# G$ C9 N3 ^/ y0 K让\w、\W、\b、\B、\d、\D、\s和\S依赖Unicode库。 re.X
$ Y7 L6 P# a! z+ ere.VERBOSE& B) Z; _: S) x+ g4 K6 `
运用这个标志,你可以写出可读性更好的正则表达式:除了在方括号内的和被反斜杠转义的以外的所有空白字符,都将被忽略,而且每行中,一个正常的井号后的所有字符也被忽略,这样就可以方便地在正则表达式内部写注释了。也就是说,下面两个正则表达式是等效的: a = re.compile(r"""\d + # the integral part) r8 f4 L# k4 L3 K! b0 w! P
\. # the decimal point \d * # some fractional digits""", re.X)b = re.compile(r"\d+\.\d*")re.search(pattern, string[, flags])2 K; n# w1 P9 H v& K
扫描string,看是否有个位置可以匹配正则表达式pattern。如果找到了,就返回一个MatchObject的实例,否则返回None,注意这和找到长度为0的子串含义是不一样的。搜索过程受flags的影响。
. i9 E f8 r G' ]+ C% Cre.match(pattern, string[, flags])
& \) }( @0 h! b" W1 n5 Q+ g5 C7 e3 y8 v
如果字符串string的开头和正则表达式pattern匹配的话,返回一个相应的MatchObject的实例,否则返回None 注意:要在字符串的任意位置搜索的话,需要使用上面的search()。 re.split(pattern, string[, maxsplit=0])
# V% `6 t3 l% ~5 W# J% K% \/ Z, `' s
用匹配pattern的子串来分割string,如果pattern里使用了圆括号,那么被pattern匹配到的串也将作为返回值列表的一部分。如果maxsplit不为0,则最多被分割为maxsplit个子串,剩余部分将整个地被返回。 >>> re.split('\W+', 'Words, words, words.')['Words', 'words', 'words', ''>>> re.split('(\W+)', 'Words, words, words.')['Words', ', ', 'words', ', ', 'words', '.', ''>>> re.split('\W+', 'Words, words, words.', 1)['Words', 'words, words.']& G) _5 D8 @0 o) i) ]
如果正则有圆括号,并且可以匹配到字符串的开始位置的时候,返回值的第一项,会多出一个空字符串。匹配到字符结尾也是同样的道理: >>> re.split('(\W+)', '...words, words...')['', '...', 'words', ', ', 'words', '...', '']
5 C$ [6 K- e+ ?; N注意,split不会被零长度的正则所分割,例如: >>> re.split('x*', 'foo')['foo'>>> re.split("(?m)^$", "foo\n\nbar\n")['foo\n\nbar\n']
2 T/ @$ l0 r! Pre.findall(pattern, string[, flags])
4 ] k$ _5 o- l; M
' R6 D' V N3 x8 I/ z1 E2 g p6 C以列表的形式返回string里匹配pattern的不重叠的子串。string会被从左到右依次扫描,返回的列表也是从左到右一次匹配到的。如果pattern里含有组的话,那么会返回匹配到的组的列表;如果pattern里有多个组,那么各组会先组成一个元组,然后返回值将是一个元组的列表。
# C) U2 E* z! H& ~7 O! v由于这个函数不会涉及到MatchObject之类的概念,所以,对新手来说,应该是最好理解也最容易使用的一个函数了。下面就此来举几个简单的例子: [backcolor=rgb(245, 245, 245) !important][url=][/url]' X, p/ A$ \9 H7 R& m. o) K' |
#简单的findall>>> re.findall('\w+', 'hello, world!')['hello', 'world'#这个返回的就是元组的列表>>> re.findall('(\d+)\.(\d+)\.(\d+)\.(\d+)', 'My IP is 192.168.0.2, and your is 192.168.0.3.')[('192', '168', '0', '2'), ('192', '168', '0', '3')]re. finditer(pattern, string[, flags])[backcolor=rgb(245, 245, 245) !important][url=][/url]; \$ K' q& _+ c; x _) o
1 _, W. q4 M' d* I5 P2 r和上面的findall()类似,但返回的是MatchObject的实例的迭代器。
1 [9 x( Z9 v7 {9 ]还是例子说明问题: [backcolor=rgb(245, 245, 245) !important][url=][/url]& V* v+ A" ]9 y& b+ H! t" Z, D
>>> for m in re.finditer('\w+', 'hello, world!'): print(m.group()) helloworld>>> [backcolor=rgb(245, 245, 245) !important][url=][/url]+ c+ s) `0 `9 h% N" K, c9 X
0 e$ d9 ^ T% a+ [re.sub(pattern, repl, string[, count])
+ ^6 ^0 |: e V/ G Y) O
, `5 J6 t* v& R替换,将string里,匹配pattern的部分,用repl替换掉,最多替换count次(剩余的匹配将不做处理),然后返回替换后的字符串。如果string里没有可以匹配pattern的串,将被原封不动地返回。repl可以是一个字符串,也可以是一个函数(也可以参考我以前的例子)。如果repl是个字符串,则其中的反斜杆会被处理过,比如 \n 会被转成换行符,反斜杆加数字会被替换成相应的组,比如 \6 表示pattern匹配到的第6个组的内容。0 E! J: F7 R. {& M
例子: >>> re.sub(r'def\s+([a-zA-Z_][a-zA-Z_0-9]*)\s*\(\s*\):', r'static PyObject*\npy_\1(void)\n{', 'def myfunc():')'static PyObject*\npy_myfunc(void)\n{'
5 D5 H6 `- w4 \+ W0 r& E. I1 t9 D0 R7 z% c5 ^6 s+ _
如果repl是个函数,每次pattern被匹配到的时候,都会被调用一次,传入一个匹配到的MatchObject对象,需要返回一个字符串,在匹配到的位置,就填入返回的字符串。+ k6 N' h' ?" m6 Z1 A( m
例子: [backcolor=rgb(245, 245, 245) !important][url=][/url]0 s1 p5 n" E; L/ T2 Z& l5 ]+ G, t5 |
>>> def dashrepl(matchobj): if matchobj.group(0) == '-': return ' ' else:
9 _7 \+ V/ y& L. _ return '-' >>> re.sub('-{1,2}', dashrepl, 'pro----gram-files')'pro--gram files'>>> [backcolor=rgb(245, 245, 245) !important][url=][/url]
* X) i/ h/ e) b: U8 O [# v
% M& R' [ ? t: e V- o零长度的匹配也会被替换,比如: >>> re.sub('x*', '-', 'abcxxd')'-a-b-c-d-'>>> . W* `2 C |; \+ q$ {
特殊地,在替换字符串里,如果有\g这样的写法,将匹配正则的命名组(前面介绍过的,(?P...)这样定义出来的东西)。\g这样的写法,也是数字的组,也就是说,\g<2>一般和\2是等效的,但是万一你要在\2后面紧接着写上字面意义的0,你就不能写成\20了(因为这代表第20个组),这时候必须写成\g<2>0,另外,\g<0>代表匹配到的整个子串。
\: @; t( [7 k$ Y0 U% @/ y7 w例子: >>> re.sub('-(\d+)-', '-\g<1>0\g<0>', 'a-11-b-22-c')'a-110-11-b-220-22-c'>>> * @" T( G6 ^1 E r$ n" m8 v3 I
' G n% |3 n+ Y& \- e( o% D2 l S. Y0 H
____author___JayeHe- Z5 {% a8 T1 V3 e
|

 /4
/4 
 |返回首页|Archiver|小黑屋|易陆发现技术论坛
( 蜀ICP备2026014127号-1 )
|返回首页|Archiver|小黑屋|易陆发现技术论坛
( 蜀ICP备2026014127号-1 )

 窥视卡
窥视卡 雷达卡
雷达卡 发表于 2018-9-20 15:21:53
发表于 2018-9-20 15:21:53
 4 \( ^2 P! Z) K' x
4 \( ^2 P! Z) K' x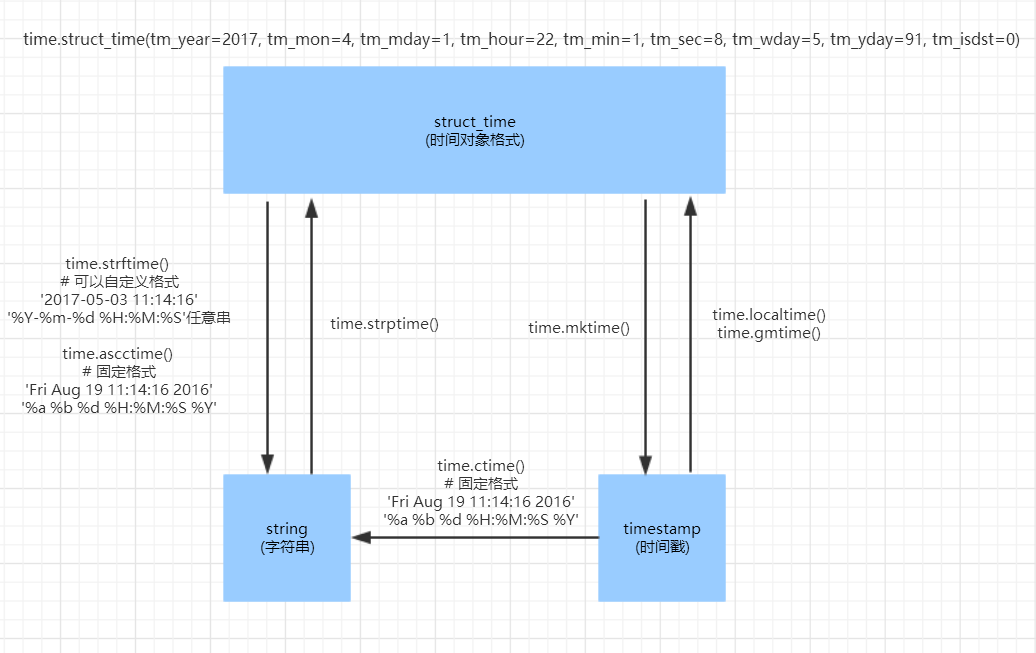 ) A ~- J# ]5 F
) A ~- J# ]5 F
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜